
Project "x.GPT"
& why I am (of course) starting an AI company

Resists the masculine urge to weigh in on the SVB drama..

Greetings Friends,
Last week I continued my thought on where the value would amass in the AI sector. I argued that the lower part of the stack would be largely balkanized, with the upper part of the stack being democratized. I’ve discussed this democratization in a similar fashion in Middleman America, where I talked about how “when tech breathes in”, it creates a large technical gap between the codebase and the eventual end user interface. This creates a lot of bureaucratic bloat, the price you pay for the democratization of advancement.
AI is taking this large gap to the extreme. Instead of the codebase being something so “complicated” that you need several layers of management abstracted away from it, it actually is a black box. We know how the machine is built, and how it learns, and how it determines its output, but we don’t actually know why it outputs exactly what it does each time. We can’t predict with certainty what it is going to say in a given scenario. This doesn’t imply sentience of course, but it adds a layer of mystique to the protocol. This mystique has the potential to generate an infinite amount of content, and with it, and infinite amount of product market fit, and an infinite amount of bureaucratic bloat. Like with speech though, the solution to bad product is more product, not less. Let the ideas compete in the free market. Life is not a zero sum game. It’s best to participate in increasing the total pie, and not concentrate too hard on who might extractively nibbling at the crust.
So of course I am starting an AI company.
Piggybacking off of last week’s teaser, we are now starting to see visions of all these interesting things being built on top of the AI. Everyone is using the same LLM (OpenAI’s API), which we all know by now is purposefully only trained on internet history up to a couple of years ago. Of course the API will eventually include more and more recent things, especially as it learns from the 100 million users that have been chatting with it, but this does expose an obvious product deficiency. Like “actual intelligence”, the Artificial Intelligence doesn’t know what it doesn’t know. You can’t ask it to summarize the Lakers game because it doesn’t have the box score. You can’t ask it to do your taxes because it doesn’t have your W2. Like I said last week, the immediate future of AI applications is going to be bespoke embeddings. In other words, adding your own data into the AI.
The immediate future of AI applications is going to be bespoke embeddings.
The only mainstream mechanism for users to get information into the AI right now is to chat it in via copy/paste. ChatGPT is infinitely useful, but how much better would it be if it knew more about your life, job, or specific area of interest? Obviously everyone is thinking about this, and many people are working on tools to create connections from a data source to the AI, but there aren’t many useful interfaces making it easy for the end user. That’s all about to change.
Project “x.GPT”
I’ve teamed up with some brilliant people from Harvard and USC to create a product that we will be launching very soon. It is a consumer-friendly file-uploader that allows you to train and share your own AI model. Born out of a project with a much larger scope to be revealed at a later date, “x.GPT” is a piece of necessary technology that will stand alone as its own product.
There are three main features to the app:
Multi-Format File Uploader.
Bespoke Model Customizer.
Public Sharing Network.
Multi-Format File Uploader
Several sites already exist that allow certain types of specific files to be uploaded to an AI, but they cater to a specific file type. One for PDF, one for XLSX, one for JPEG, all with clunky interfaces to boot. Tangentially, there is more and more open source code being developed every minute (!!) that builds out connectors to other file types, but none of them have a home on a front end anywhere. Alongside the aforementioned PDF, XLSX, JPEG, we are building out the front end to enable voice notes, memos, DOCX, PPTX, CSV, JSON, Notion, Twitter, Gmail, Slack, Reddit, Youtube Transcript, WhatsApp, Wikipedia, and general simple web pages. All in one place, all with the same simple, intuitive UI.
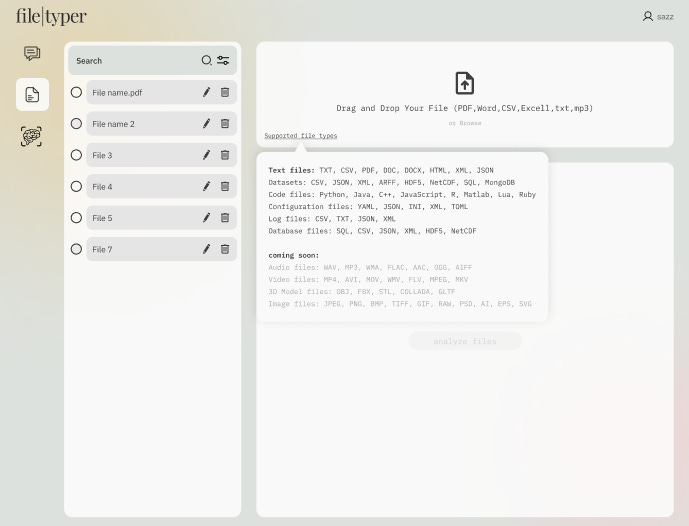
Bespoke Model Customizer
All of these files are uploaded and embedded to the OpenAI LLM to create your own personal AI model, which you can name, describe, and codify appropriately. You can also create as many personal models as you would like. If you want to upload the entire transcript of every Huberman Lab podcast episode, have at it. That can be a standalone model, or you can supplement it with your daily voice notes about how much you slept, ate, drank, and exercised.
Once you have a model created, you can always add to it or subtract from it by way of the intuitive UI, so as to never forget which content each model contains. Of course the next step is to interact and enjoy your creation. If you’ve mixed the Huberman Lab content with your own personal health journal, you can start to ask the AI if you’re sufficiently optimizing your circadian rhythms, or if your diet needs tweaking, etc. This opens the door to endless possibilities. The only limit to the use cases are the creativity of the users.

Public Sharing Network
What fun would it be to create a Huberman Lab AI embedding and not share it with the world? Once your model is created and appropriately tagged, you can choose to make it public. Of course, you will only want to make the base model public and keep your personal additions private. This allows everyone to add their own personalization to the public model, perhaps riffing further and adding a corpus of Buddhist texts scraped from the internet, or a few military exercise PDFs from an old hard drive. Thus, the community adds the “je ne sais quoi” that is so vitally important for network effects to take hold.

This project is soon to be released in beta form, starting with a few popular file connectors and building out the rest as community demands evolve. Bespoke AI embeddings are not a new concept, but no one is executing on them well. The few that exist do so as standalone products (a single custom embedding per webpage) and force the user to use their own OpenAI API key (as if the average consumer has one), which comically saves the creator the fractions of a penny it would cost to query their model.
This is the future of AI! Like humans, Large Language Models will only get better over time if they are constantly learning. Increasing the number of avenues (connectors) by which you can feed it curated data, and getting people interested in curating their own models, increases the bandwidth in which we can feed the AI, and ultimately results in better and more specific use cases.
Remember, this product is only the first step in a long, arduous roadmap to another end. This connector and curation technology is important, however, and being first to market in a lightning fast ecosystem is a huge win. We are excited about the technology and the interface, but the community is the x-factor. This should generate some buzz and excitement around the company that we can parlay into future fundraising efforts.
Hope y’all enjoyed the first look. I am humbled to have generated such a loyal audience, so I don’t mind leaking this information a little bit early. Stay tuned for future updates!
Congratulations! This is awesome.